


家里书架上,有没有一套放着没读完的《资治通鉴》?
很多人买过。十六册一摞,摆着很有排面。然后就再也没打开过。
不是不想读。是每次翻开第一页,看到密密麻麻的文言文,心里就有声音说:"等准备好了再说。"一等就是好多年。
下面看这样图你就清晰了。

这本书的真正门槛
司马光花了 19 年 修这套书。跨度 1362 年,294 卷,讲的是中国历史上最复杂的那段时间。
但内容不是问题,故事比任何宫斗剧精彩。真正的问题是:
读到第 20 卷的时候,完全不记得第 3 卷那个人是谁了。
人物太多,关系太乱。"赵籍"知道,"赵侯"也知道,但不知道是同一个人。记住了战役地名,却不知道那个地方在现在哪里。
这个感受,可能你也有过。
有人用代码,把它做成了一个可视化网站
GitHub 上有个开源项目,叫 zizhitongjian。一个程序员维护了好几年。
他做的事,一句话讲:把全文喂给 AI,把里面所有的人物、地点、事件、关系全部提取出来,做成一个可以交互的系统。
打开在线演示,第一眼就是这个画面:
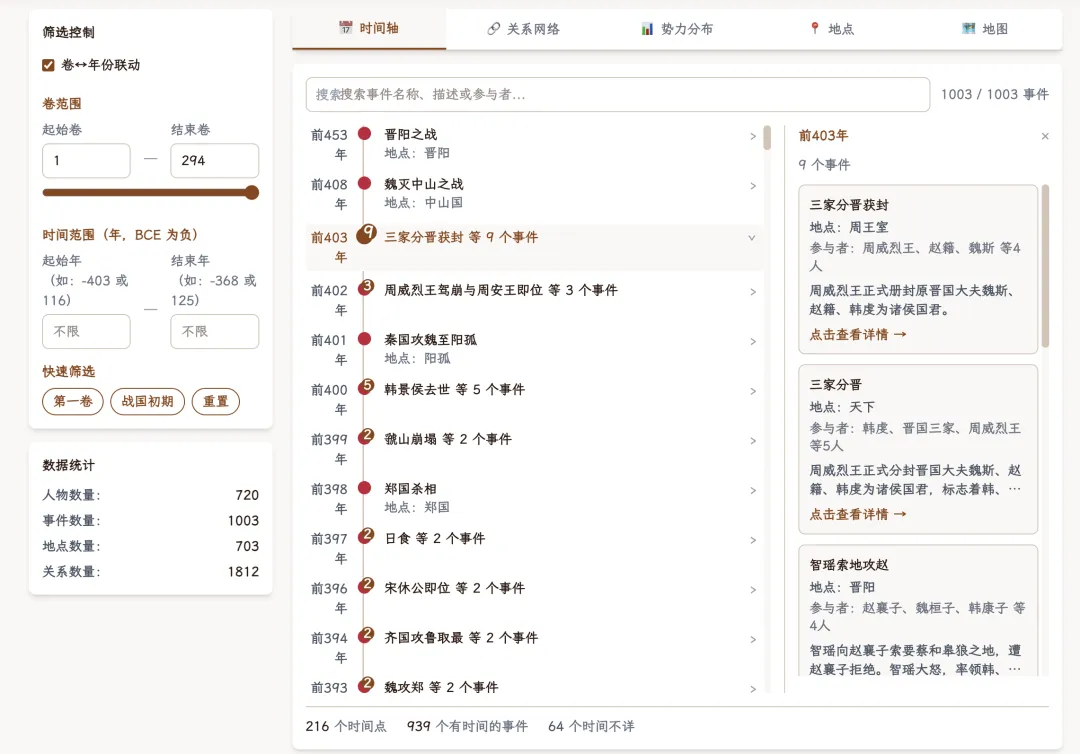
主界面与时间轴👆
左下角有个"数据统计":
人物:720 事件:1003 地点:703 关系:1812
——而这还只是 已提取的部分卷次。
也就是说,全书还没拆完,就已经拆出了 720 个人、1003 件事、703 个地点、1812 种交错关系。
不是读不进去,是这个密度本来就不适合"从头读到尾"。
三个维度,把这本书拆开了
时间维度:1003 个事件全部排在可拖动的时间轴上。
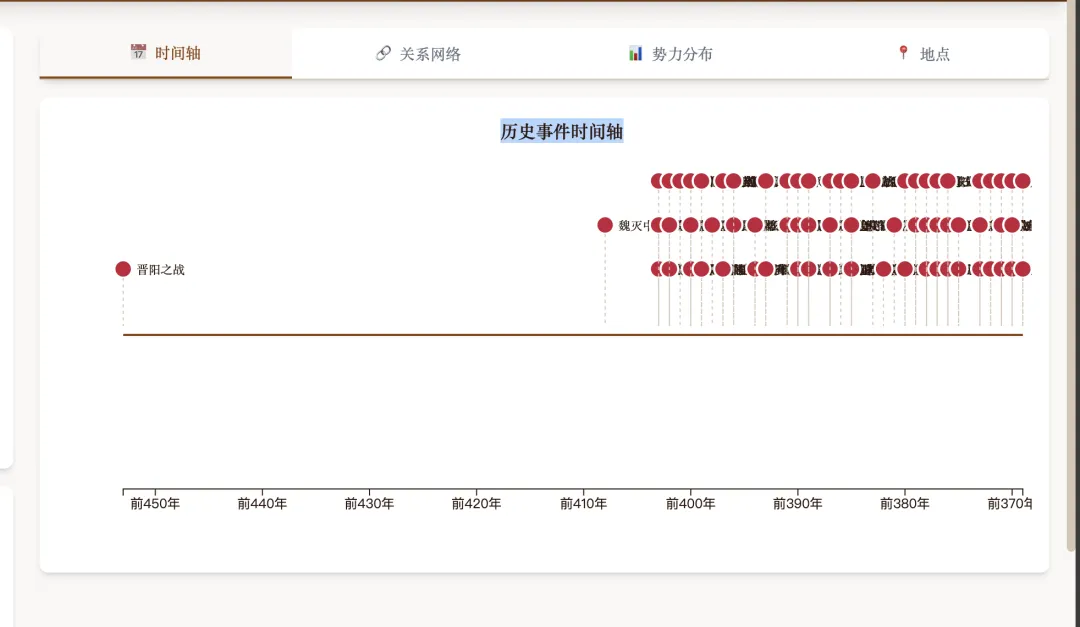
时间轴细节👆
拖到公元前 403 年,那一年挤了 9 个 事件——"三家分晋获封"是其中之一。司马光就是从这一年起笔的。
光看红点的密度,就能看见历史的"形状"——空白的年份是太平年代,密集的年份是改朝换代。这是从书里读不出来的判断。
空间维度:703 个地点全部用高德地图做了地理编码,映射到现代地图上。
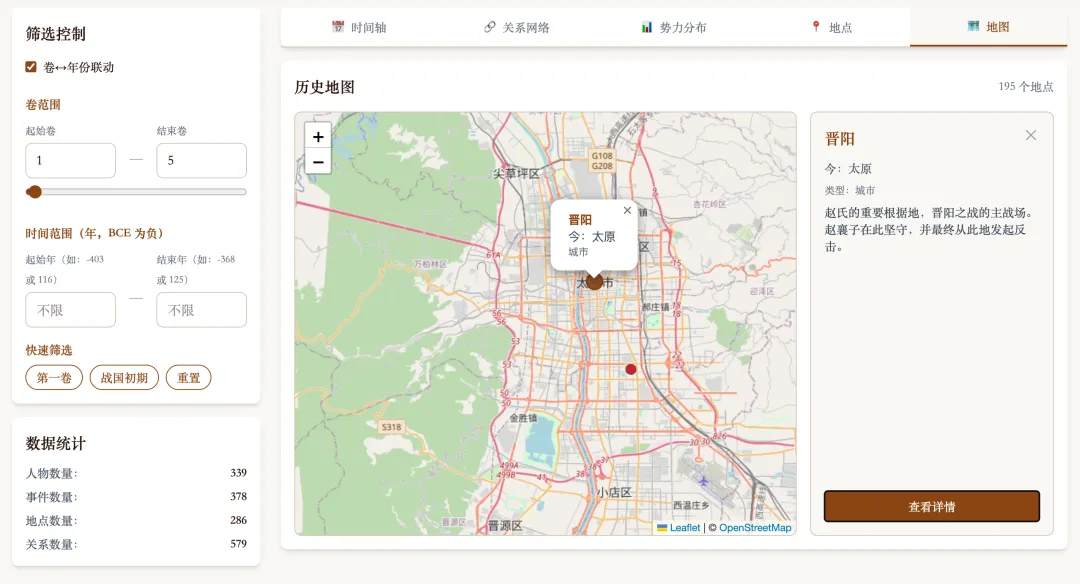
地图模式👆
点开"晋阳",地图跳到山西太原一带。那是赵氏死守三年最后翻盘的地方。"晋阳"两个字,第一次在地图上有了形状。
人物维度:720 个人物、1812 条关系,做成一张力导向图。
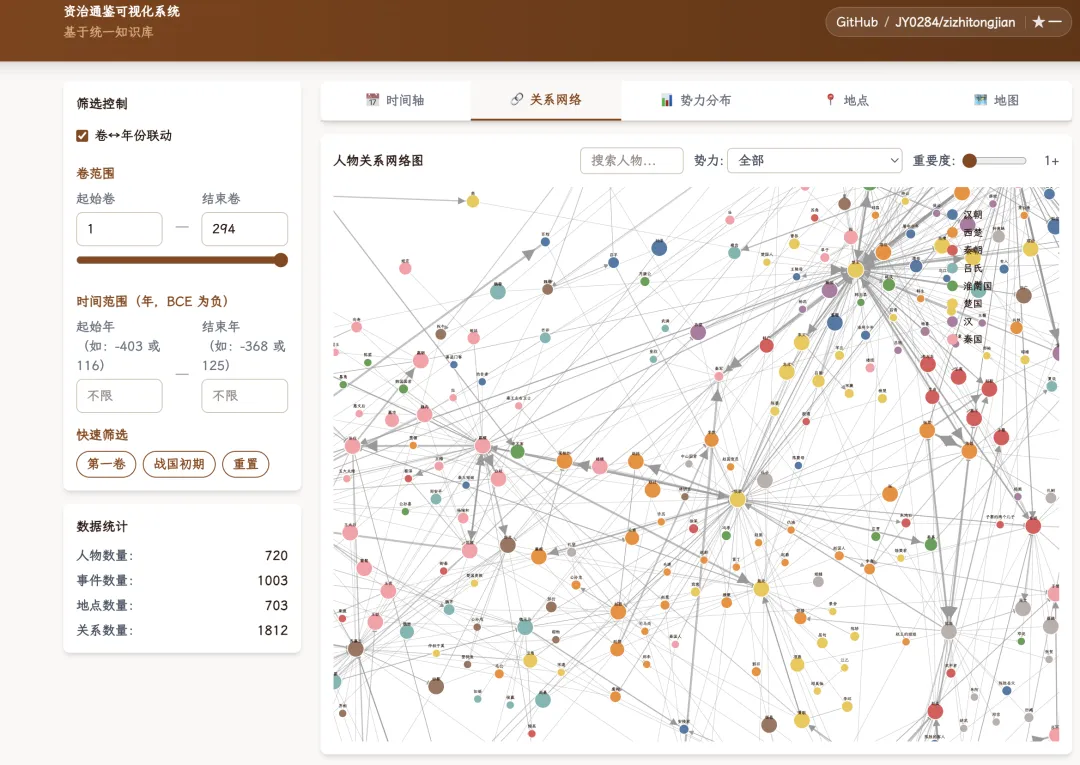
关系网络👆
点击赵籍,关系线散开。再点到智伯、韩康子、魏桓子——"三家分晋"在脑子里第一次有了 结构,而不是几个孤立的名字。
很多人在这个页面一坐就是两小时。是那 1812 条线本身让人走不开。
难的不是功能,是算法
720 这个数字背后有个隐藏难点。
"赵籍"、"赵侯"、"赵烈侯"——三个字符串,同一个人。普通的文本处理会把它们当成三个人,关系网会乱成一团。
这个项目用 Union-Find 算法 把同一人物的所有称呼合并成一个节点。同时还要处理"人地分离"——"赵"是人名(赵籍)还是国名(赵国)?混在一起,703 个地点和 720 个人物就会互相污染。
读史书拦住人的,从来不只是内容,更是语言本身的密度。这个项目用代码,把这层密度剥开了。
它的价值
大多数"历史科普",是把古文翻成白话文,让你"感觉更有趣了"——你接收的是别人咀嚼过的内容。
这个项目不一样,它 提供工具,让你自己探索原始内容。
1003 个事件是时间索引。703 个地点是坐标系。720 个人物 + 1812 条关系是人物图谱。文白对照是翻译。
读《资治通鉴》的方式,从"翻一本书"变成"在一个历史数据库里探索"。
从一个感兴趣的人物开始,看他的关系网,沿着关系走进他所在的时代,在地图上找到那些战争发生的地点——这才是。
还没做完的部分
这些数字还在增长。整本 294 卷全部提取完,可能会是上万个事件、几千个地点、上万种关系。
那张关系网会变成什么样子,现在还想象不出来。
项目 TODO 里还写着另一个功能:"对话交互式资治通鉴"——以后可以直接问这本书问题,AI 从全书知识库里给你找线索。
值得期待。
项目开源,代码在 GitHub 上,在线演示直接打开就能用。
- GitHub:https://github.com/JY0284/zizhitongjian
- 在线体验:https://zztj.wawuyu.cn
- 文白对照阅读:https://jy0284.github.io/zizhitongjian
点开那张关系网,随便选一个认识的历史人物,沿着线走下去。
你认识的历史,和你看到的这张网,可能不是同一个历史。
TM3 个月前
发表在:CrossDesk | RustDesk、ToDesk平替Hey there! I c᧐uld h...
刀客7 个月前
发表在:近期发现的2个挂机应用 | 未测试 | 有兴趣的可以尝试一下@j:这就尴尬 这2个我暂时还没有去尝...
j7 个月前
发表在:近期发现的2个挂机应用 | 未测试 | 有兴趣的可以尝试一下vyx掛了16個IP快一個月了完全沒流量...
刀客8 个月前
发表在:Wipter - 全网首发 - 批量多开放大 - 保姆级教程!@ysbg:官方是游戏规则定制者
ysbg8 个月前
发表在:Wipter - 全网首发 - 批量多开放大 - 保姆级教程!为什么要检测多开?我觉得没有意义呀,因为...
刀客8 个月前
发表在:被Ban的Office-E5迎来救赎 | 新的希望 | 100GB-Outlook 和 5TB-OneDrive@pipi:哈哈
pipi8 个月前
发表在:被Ban的Office-E5迎来救赎 | 新的希望 | 100GB-Outlook 和 5TB-OneDrive不错不错,按照教程搞了个E3
刀客9 个月前
发表在:[装死,目测跑路]挂机网赚 - Earn.Cc@清风:近期会整理一期文章发布
清风9 个月前
发表在:[装死,目测跑路]挂机网赚 - Earn.Cc希望刀哥把利润高的标注一下谢谢
刀客9 个月前
发表在:[装死,目测跑路]挂机网赚 - Earn.Cc@清风:好的.感谢支持