


2025年11月18日 11:20 UTC(时区下同),Cloudflare 核心网络的流量传输出现严重故障。对于试图访问使用了Cloudflare-CDN的用户的站点的互联网用户而言,这表现为显示 Cloudflare 网络内部故障的错误页面。
刀客的大不部分网站也没能幸免,损失惨重。
此次故障并非由任何形式的网络攻击或恶意活动直接或间接导致。
相反,该问题是由我们某个数据库系统的权限变更引发的。这一变更导致数据库向我们“机器人管理”系统使用的“特征文件”错误的输出了多重条目,致使该文件的大小翻了一倍。随后,这个超出预期大小的特征文件被推送到了构成我们网络的所有机器上。
这些机器上运行的流量路由软件会读取该特征文件,以确保我们的机器人管理系统能够随时应对不断变化的威胁。然而,该软件对特征文件的大小设定了上限,而翻倍后的文件超过了这一限制,从而导致软件崩溃。
起初,我们曾错误地怀疑这些问题是由超大规模 DDoS 攻击引起的,但随后我们准确锁定了核心问题,并成功阻止了该异常特征文件的进一步传播,将其替换为早期的正常版本。核心流量在 14:30 左右基本恢复正常。在随后的几个小时里,随着流量大量涌回 Cloudflare,我们致力于缓解网络各部分增加的负载。截至 17:06,Cloudflare 的所有系统均已恢复正常运行。
我们对此次故障给客户及广大互联网用户造成的影响深表歉意。鉴于 Cloudflare 在互联网生态系统中的重要地位,我们任何系统的任何中断都是不可接受的。我们的网络在一段时间内无法路由流量,这令我们每一位团队成员都倍感痛心。我们深知今天辜负了大家的信任。
本文是对发生经过、故障系统及失效流程的深度复盘。这也是我们为确保此类中断不再发生所制定的计划的起点,而非终点。
故障详情
下表显示了 Cloudflare 网络提供的 5xx HTTP 错误状态码的数量。通常情况下,该数值应极低,而在故障开始前也确实如此。
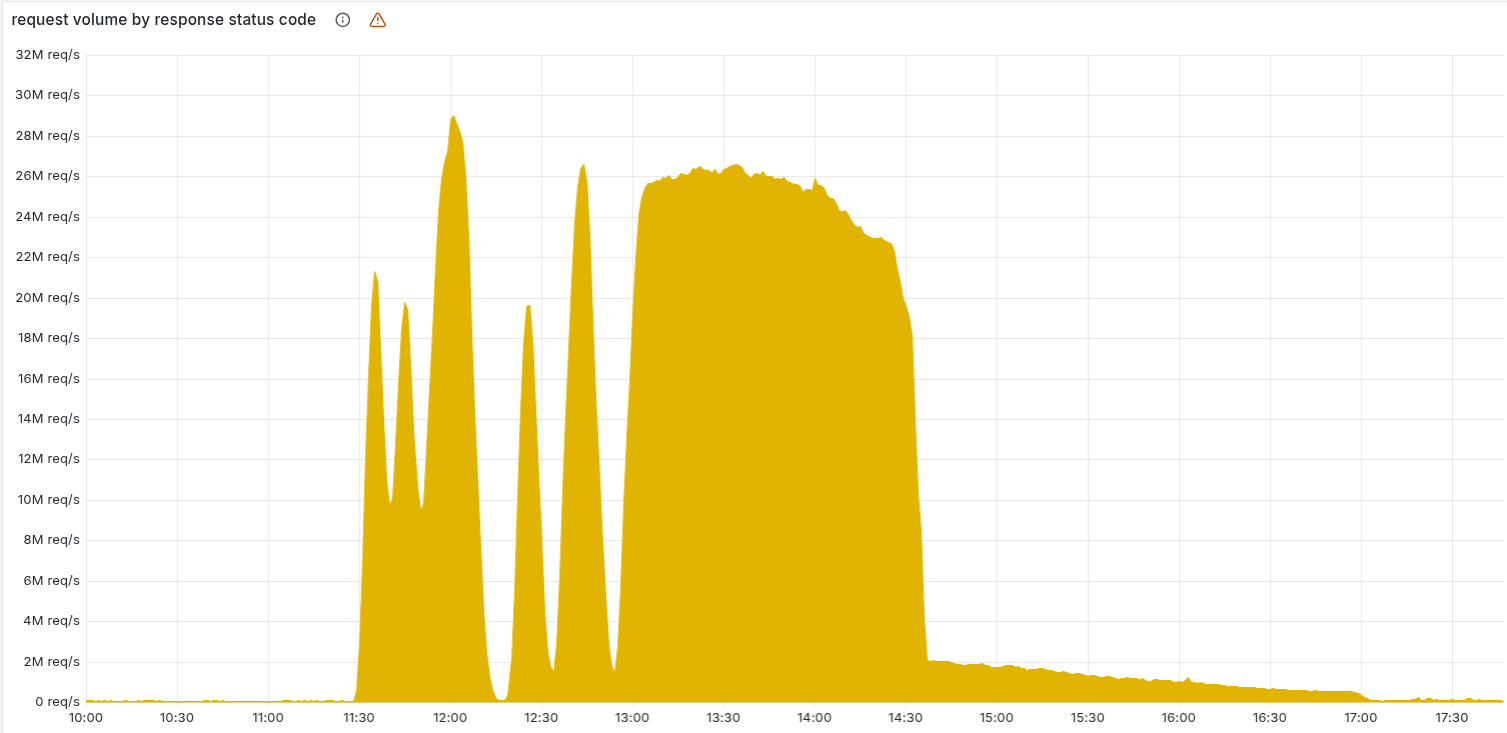
11:20 之前的数值是我们网络中观测到的 5xx 错误的预期基线。随后的激增及波动表明我们的系统因加载了错误的特征文件而失效。值得注意的是,系统会随后恢复一段时间。对于内部错误而言,这种表现非常反常。
其原因在于,该文件是由一个运行在 ClickHouse 数据库集群上的查询每五分钟生成一次的,而该集群当时正逐步进行更新以改进权限管理。只有当查询运行在已更新的那部分集群上时,才会生成错误数据。结果就是,每五分钟就有可能生成一组好或是坏的配置文件,并迅速传播到整个网络。
这种波动使得故障排查变得模糊不清,因为整个系统会恢复,然后随着好坏配置文件的交替分发而再次失效。最初,这让我们误以为是遭到了攻击。最终,当所有 ClickHouse 节点都开始生成错误的配置文件后,波动停止,系统稳定处于故障状态。
错误一直持续到我们从 14:30 开始识别并解决根本问题。我们通过停止生成和传播错误的特征文件,并手动将已知的正确文件插入特征文件分发队列,随后强制重启核心代理,解决了该问题。
上图表中的剩余长尾代表我们的团队正在重启那些进入不良状态的剩余服务,5xx 错误代码量在 17:06 恢复正常。
以下服务受到了影响:
| 服务 / 产品 | 影响描述 |
|---|---|
| 核心 CDN 和安全服务 | 出现 HTTP 5xx 状态码。本文最开始的截图展示了最终用户看到的典型错误页面。 |
| Turnstile | Turnstile 无法加载。 |
| Workers KV | Workers KV 返回了显著升高的 HTTP 5xx 错误,因为对 KV “前端”网关的请求因核心代理故障而失败。 |
| Dashboard (控制台) | 虽然控制台主要功能正常,但由于登录页面上的 Turnstile 不可用,大多数用户无法登录。 |
| Email Security | 虽然邮件处理和投递未受影响,但我们观察到暂时无法访问 IP 信誉源,这降低了垃圾邮件检测的准确性,并阻止了一些新域名期限检测的触发,未观察到严重的客户影响。我们还发现部分自动发件操作失败;所有受影响的邮件均已被审查并修复。 |
| Access | 从事故开始直到 13:05 启动回滚期间,大多数用户的身份验证广泛失败。现有的 Access 会话未受影响。所有失败的身份验证尝试均导致错误页面,这意味着在验证失败期间,这些用户从未到达目标应用程序。此期间成功的登录已在此次事件中被正确记录。当时尝试的任何 Access 配置更新要么直接失败,要么传播极慢。所有配置更新现已恢复。 |
除了返回 HTTP 5xx 错误外,我们还观察到在受影响期间 CDN 响应延迟显著增加。这是由于我们的调试和可观测性系统消耗了大量 CPU,这些系统会自动为未捕获的错误添加额外的调试信息。
Cloudflare 如何处理请求,以及今天何处出了错
每一个发往 Cloudflare 的请求都会经过我们网络中一条定义明确的路径。它可能来自加载网页的浏览器、调用 API 的移动应用,或来自其他服务的自动化流量。这些请求首先终止于我们的 HTTP 和 TLS 层,然后流入我们的核心代理系统(我们称之为 FL,即 "Frontline"),最后通过 Pingora,由其执行缓存查找或在需要时从源站获取数据。
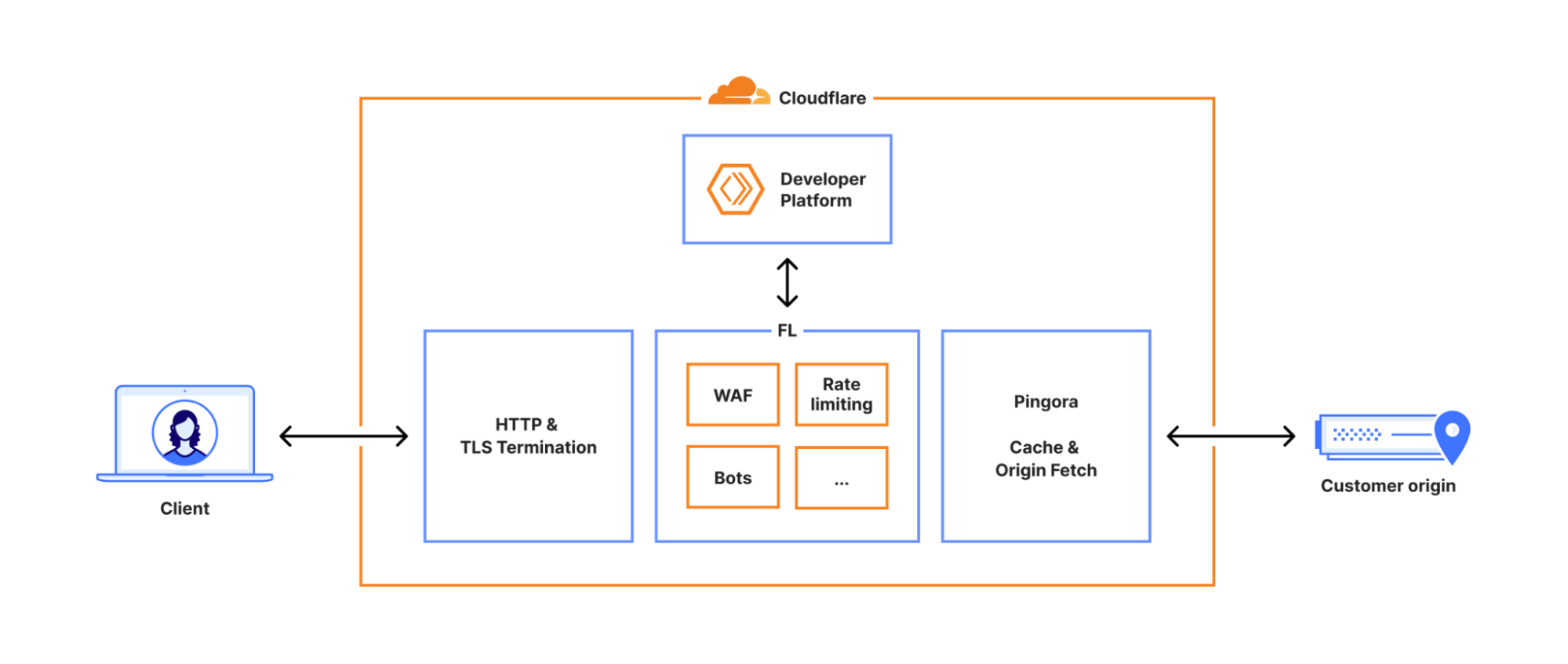
当请求通过核心代理时,我们会运行网络中可用的各种安全和性能产品。代理会应用每个客户独特的配置和设置,从执行 WAF 规则和 DDoS 防护,到将流量路由至开发者平台和 R2。它是通过一组特定领域的模块来实现这一点的,这些模块将配置和策略规则应用于通过代理的流量。
其中一个模块——机器人管理,就是今天故障的源头。
Cloudflare 的 Bot Management 包含一个机器学习模型(以及其他系统),我们要用它为流经网络的每个请求生成机器人评分。我们的客户使用机器人评分来控制允许哪些机器人访问其站点,或拒绝哪些机器人。
该模型将一个“特征”配置文件作为输入。在这种语境下,特征是机器学习模型用来预测请求是否自动化的一种单独属性。特征配置文件是这些单独特征的集合。
这个特征文件每几分钟刷新一次,并发布到我们要全网,使我们能够对互联网上流量流的变化做出反应。它使我们能够应对新型机器人和新的机器人攻击。因此,鉴于恶意行为者变换战术极为迅速,频繁且快速地推出该文件至关重要。
生成此文件的底层 ClickHouse 查询行为发生了变更(下文详述),导致该文件中包含大量重复的“特征”行。这改变了此前大小固定的特征配置文件的大小,导致 Bot 模块触发错误。
结果是,处理客户流量的核心代理系统对任何依赖 Bot 模块的流量返回了 HTTP 5xx 错误代码。这也影响了依赖核心代理的 Workers KV 和 Access 服务。
与此事件无关的是,我们当时正在(且目前仍在)将客户流量迁移到新版本的代理服务,内部称为 FL2。这两个版本都受到了该问题的影响,尽管观察到的影响有所不同。
部署在新 FL2 代理引擎上的客户观察到了 HTTP 5xx 错误。使用我们旧代理引擎(称为 FL)的客户未看到错误,但机器人评分未能正确生成,导致所有流量收到的机器人评分为零。部署了拦截机器人规则的客户会看到大量的误报。未在其规则中使用我们机器人评分的客户则未受影响。
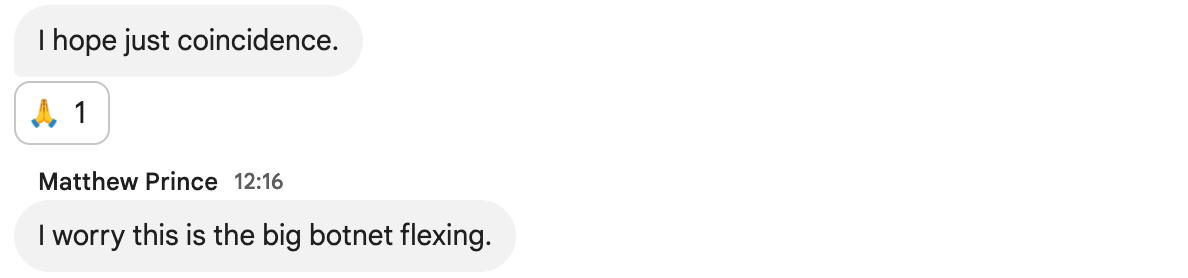
另一个明显的症状干扰了我们的判断,让我们误以为这可能是一次攻击:Cloudflare 的状态页面(Status Page)瘫痪了。状态页面完全托管在 Cloudflare 基础设施之外,不依赖于 Cloudflare。虽然事后证明这只是巧合,但这导致部分负责诊断问题的团队成员认为攻击者可能同时针对我们的系统和状态页面。当时访问状态页面的用户会看到一条错误消息:

在内部事故聊天室中,我们曾担心这可能是近期一系列高流量 Aisuru DDoS 攻击的延续:
查询行为的变更
我在上文提到,底层查询行为的变更导致特征文件包含大量重复行。相关的数据库系统使用的是 ClickHouse 软件。
为了便于理解,了解 ClickHouse 分布式查询的工作原理很有帮助。一个 ClickHouse 集群由许多分片(shards)组成。为了从所有分片查询数据,我们在名为 default 的数据库中拥有所谓的分布式表(由表引擎 Distributed以此支持)。Distributed 引擎查询 r0 数据库中的底层表。底层表是数据在 ClickHouse 集群每个分片上实际存储的地方。
对分布式表的查询通过一个共享系统账户运行。为提高分布式查询安全性和可靠性,我们正在努力使其改在初始用户账户下运行。
在今天之前,ClickHouse 用户在查询 ClickHouse 系统表(如 system.tables 或 system.columns)中的表元数据时,只能看到 default 数据库中的表。
由于用户已经拥有对 r0 中底层表的隐式访问权限,我们在 11:05 进行了一项变更,使这种访问权限变为显式,以便用户也能看到这些表的元数据。通过确保所有分布式子查询都能在初始用户下运行,可以更细粒度地评估查询限制和访问授权,避免一个用户的错误子查询影响其他用户。
上述变更导致所有用户都能访问其有权访问的表的准确元数据。不幸的是,过去曾有一些假设,即像下面这样的查询返回的列列表将仅包括 default 数据库:
SELECT name, type
FROM system.columns
WHERE table = 'http_requests_features'
order by name;请注意,该查询并未过滤数据库名称。随着我们逐步向给定 ClickHouse 集群的用户推出显式授权,在 11:05 的变更后,上述查询开始返回列的“重复项”,因为其中包括了存储在 r0 数据库中的底层表。
不幸的是,Bot Management 特征文件生成逻辑正是执行了这类查询,以构建本节开头提到的文件所需的每个输入“特征”。
上述查询返回的列列表类似于以下所示(简化示例):

然而,作为授予用户额外权限的一部分,响应现在包含了 r0 模式的所有元数据,这实际上使响应中的行数增加了一倍以上,最终影响了最终文件输出中的行数(即特征数)。
内存预分配
在我们代理服务上运行的每个模块都设定了一系列限制,以避免无限制的内存消耗并预分配内存以优化性能。在这个特定实例中,Bot Management 系统对运行时可使用的机器学习特征数量有限制。目前该限制设定为 200,远高于我们需要使用的约 60 个特征。再次强调,该限制的存在是因为出于性能原因,我们会为特征预分配内存。
当包含超过 200 个特征的错误文件传播到我们的服务器时,触达了这一限制——导致系统崩溃。执行此检查并作为未处理错误源头的 FL2 Rust 代码如下所示:
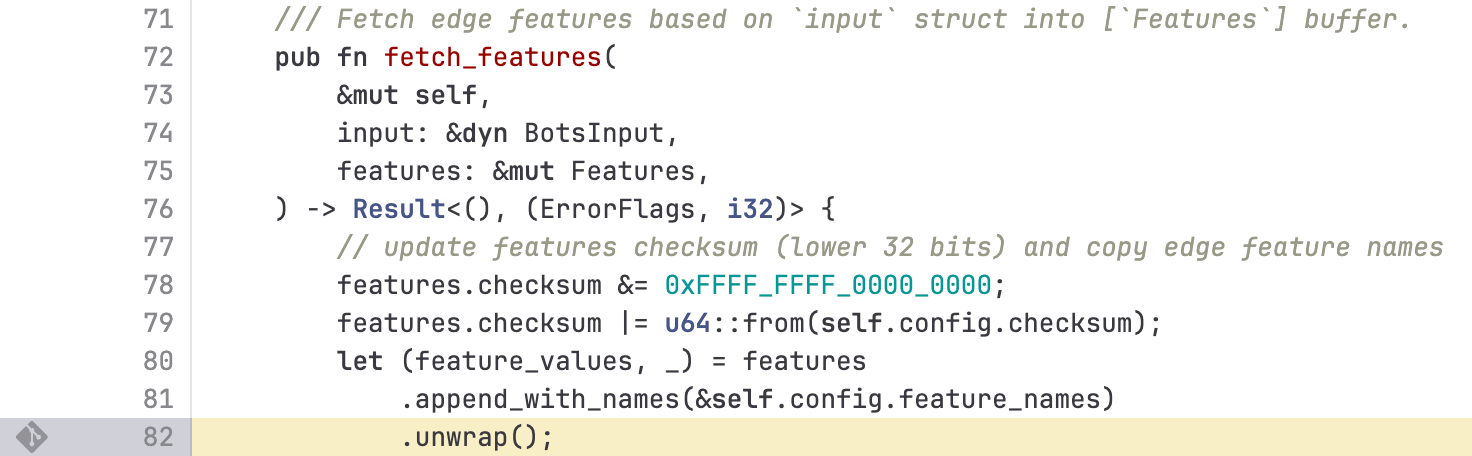
这导致了以下崩溃信息,进而导致了 5xx 错误:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
事故期间的其他影响
其他依赖我们核心代理的系统在事故期间也受到了影响。这包括 Workers KV 和 Cloudflare Access。团队在 13:04 成功减轻了对这些系统的影响,当时我们对 Workers KV 打了一个补丁以绕过核心代理。随后,所有依赖 Workers KV 的下游系统(如 Access 本身)的错误率都有所下降。
Cloudflare 控制台(Dashboard)也受到了影响,因为内部使用了 Workers KV,且 Cloudflare Turnstile 被部署作为我们登录流程的一部分。
Turnstile 受到了此次中断的影响,导致未登录的客户无法登录。这表现为两个时间段内的可用性降低:从 11:30 到 13:10,以及 14:40 到 15:30,如下图所示。
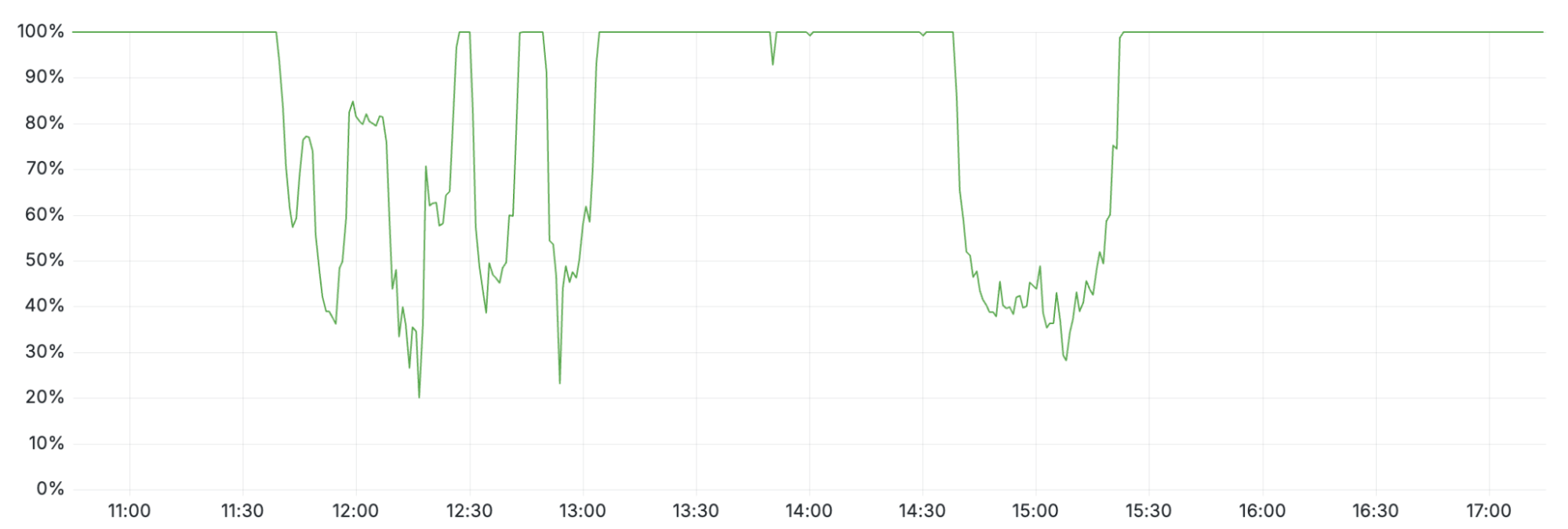
第一个时间段(11:30 到 13:10)是由于对 Workers KV 的影响,部分控制平面和控制台功能依赖于此。这在 13:10 得到恢复,当时 Workers KV 绕过了核心代理系统。
对控制台的第二个影响期发生在恢复特征配置数据之后。大量的登录尝试积压开始压垮控制台。这些积压加上重试尝试,导致延迟升高,降低了控制台的可用性。通过扩展控制平面的并发处理能力,可用性在大约 15:30 得到恢复。
修复与后续步骤
既然我们的系统已经重新上线并正常运行,我们已经开始着手研究如何加固系统以抵御未来类似的故障。具体来说,我们正在:
- 加固摄入流程: 对 Cloudflare 内部生成的配置文件采用与用户生成输入相同的摄入加固标准。
- 启用熔断机制: 为功能启用更多全局性的终止开关(kill switches)。
- 资源保护: 消除核心转储(core dumps)或其他错误报告压垮系统资源的可能性。
- 全面审查: 审查所有核心代理模块在错误条件下的故障模式。
今天是 Cloudflare 自 2019 年以来 最严重的一次中断。我们曾发生过导致控制台不可用 的中断,也有些曾导致较新功能 在一段时间内不可用。但在过去 6 年多的时间里,我们未曾再发生过导致大部分核心流量停止流经我们网络的中断。
像今天这样的中断是不可接受的。我们在架构系统时一直致力于实现对故障的高度弹性,以确保持续的流量传输。过往的每一次中断,最终都推动我们要构建更新、更具弹性的系统。
我谨代表 Cloudflare 全体团队,对今天给互联网带来的痛苦致以诚挚的歉意。
| 时间 (UTC) | 状态 | 描述 |
|---|---|---|
| 11:05 | 正常 | 部署数据库访问控制变更。 |
| 11:28 | 影响开始 | 部署到达客户环境,首次在客户 HTTP 流量中观察到错误。 |
| 11:32-13:05 | 团队调查 Workers KV 服务的流量水平升高和错误。 | 最初的症状表现为 Workers KV 响应率下降,导致对其他 Cloudflare 服务的下游影响。尝试了流量操控和账户限制等缓解措施,试图将 Workers KV 服务恢复至正常运行水平。首个自动化测试于 11:31 检测到问题,手动调查于 11:32 开始。事故响应通话于 11:35 创建。 |
| 13:05 | 实施 Workers KV 和 Cloudflare Access 绕行 — 影响减轻。 | 在调查过程中,我们对 Workers KV 和 Cloudflare Access 使用了内部系统绕行,使它们回退到我们核心代理的旧版本。虽然旧版本代理中也存在该问题,但影响较小,如下文所述。 |
| 13:37 | 工作重点转向将 Bot Management 配置文件回滚至上一个已知良好版本。 | 我们确信 Bot Management 配置文件是事故的触发点。团队分多个工作流研究修复服务的方法,其中最快的工作流是恢复文件的先前版本。 |
| 14:24 | 停止创建和传播新的 Bot Management 配置文件。 | 我们确认 Bot Management 模块是 500 错误的来源,且这是由错误的配置文件引起的。我们停止了新 Bot Management 配置文件的自动部署。 |
| 14:24 | 新文件测试完成。 | 我们观察到使用旧版本配置文件成功恢复,随即专注于在全球范围内加速修复。 |
| 14:30 | 主要影响已解决。受影响的下游服务开始观察到错误减少。 | 正确的 Bot Management 配置文件已在全球部署,大多数服务开始正常运行。 |
| 17:06 | 所有服务恢复。影响结束。 | 所有下游服务重启,所有操作完全恢复。 |
至此
整个过程的完整复盘已经呈现
希望Cloudflare以后不要再出这种大事件啦
TM3 个月前
发表在:CrossDesk | RustDesk、ToDesk平替Hey there! I c᧐uld h...
刀客7 个月前
发表在:近期发现的2个挂机应用 | 未测试 | 有兴趣的可以尝试一下@j:这就尴尬 这2个我暂时还没有去尝...
j7 个月前
发表在:近期发现的2个挂机应用 | 未测试 | 有兴趣的可以尝试一下vyx掛了16個IP快一個月了完全沒流量...
刀客8 个月前
发表在:Wipter - 全网首发 - 批量多开放大 - 保姆级教程!@ysbg:官方是游戏规则定制者
ysbg8 个月前
发表在:Wipter - 全网首发 - 批量多开放大 - 保姆级教程!为什么要检测多开?我觉得没有意义呀,因为...
刀客8 个月前
发表在:被Ban的Office-E5迎来救赎 | 新的希望 | 100GB-Outlook 和 5TB-OneDrive@pipi:哈哈
pipi8 个月前
发表在:被Ban的Office-E5迎来救赎 | 新的希望 | 100GB-Outlook 和 5TB-OneDrive不错不错,按照教程搞了个E3
刀客9 个月前
发表在:[装死,目测跑路]挂机网赚 - Earn.Cc@清风:近期会整理一期文章发布
清风9 个月前
发表在:[装死,目测跑路]挂机网赚 - Earn.Cc希望刀哥把利润高的标注一下谢谢
刀客10 个月前
发表在:[装死,目测跑路]挂机网赚 - Earn.Cc@清风:好的.感谢支持